Want to do this yourself? Grab everything you need from my Github!
Living off-grid means we have to be pretty careful with our electricity usage, especially in the winter when solar output can be a tenth of the summer highs. We don't have a huge number of mains appliances (fridge, laptops, coffee grinder, blender) and run as much as possible off 12 volts. Despite this, I honestly don't think we're missing out on anything! We use around 1kWh of electricity per day, just an eighth of the average UK household that Ofgem reckons uses 2900kWh each year.
One reason I chose to install Victron gear is that I am simply too lazy to turn an inverter on and off whenever I want to use mains power. Their inverters have a power-saving function they call AES (automatic economy switch), which keeps the inverter off and blips the power every second to see if a load is connected. If it detects a load, it switches on fully. This does restrict your choice of appliances to those without too many electronics, but for a fridge with an old-school bimetallic strip thermostat it works great.
The energy savings from using this "search mode" can be quite significant. My Multiplus 1600W inverter uses 10W when switched on with zero load, and 3W in power saving mode. Just considering the fridge, it tends to run in a 1-hour-off, 20-minutes-on cycle. So that's 18 fridge cycles per day, saving 7W * 18 hours = 126Wh compared to the inverter being left on 24 hours per day. That works out to an eighth of our average daily consumption saved. It's a much bigger deal in the winter, where the average day only gives us around 250Wh of solar power, so we're saving fully half of that!
The only downside is that picking the wattage thresholds to turn on fully can be quite finicky. These inverters don't have a current transformer on the AC output, so the power usage they report is just an estimate based on battery current and efficiency. Reactive vs resistive loads will also skew this figure. Choosing the threshold takes a bit of experimentation to pick the lowest wattage where the inverter will go into power saving with no load, but still switch on when something's plugged in. This seems to vary between inverters, but a good place to start is 25W and work upwards until it works well. Mine is just about right at 35W start and 67W stop (in reality this means a 10W load will keep the inverter on).
It's still not quite perfect, though. I noticed that newer USB-C laptop chargers will draw just a few watts to begin with, ramping up to full power after about 10 seconds. Since the "blips" in search mode only last for one AC cycle, they don't draw enough power to fully turn on the inverter before they reset. My lazy solution was to run the coffee grinder for a few seconds, but ideally I'd like to briefly disable AES, allowing the charger to ramp up before re-enabling it.
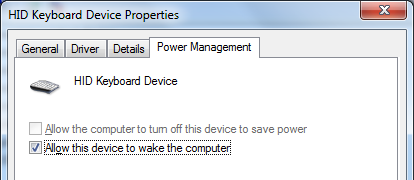
I've been playing with Node-RED a lot recently, so I figured I could find a programmatic solution. Problem is, there's a (sensible) divide in what Victron lets you access externally - you can change state but not settings, and AES is a setting so no dice. Luckily I came across this hacky workaround, which uses a digital input on the inverter to control the AES setting. The solution is described almost entirely there but took a lot of searching and keyword massaging to find, hence why I'm writing about it here!
Alright, enough backstory. This isn't a recipe website. tl;dr:
- Add a relay to your GX device
- Connect the relay to an input on the inverter
- Add assistants to the inverter to use the input state to disable AES
- Find some cute way to trigger the relay
First things first is the relay. I run Victron's Venus OS on a Raspberry Pi, so an external relay module is needed (GX devices have one or more built in). By default the Pi build only comes with one relay output, assigned to GPIO21 (pin 40), and I was already using that for my heating. Easy solution: install Kevin Windrem's SetupHelper then RpiGpioSetup, adding 5 more relays (though only 4 total are accessible through Node-RED).
I then switched out my 1-relay module with a 4-relay one. For single relay modules, it seems like any old 5v relay module will do (they must be powered by 5v, but a 3.3v GPIO will trigger it). But when you go larger, you have to be careful - many of these seem to be active-low rather than active-high, and additionally require 5v to trigger them. Active-low doesn't work for Venus OS, as during the Pi's startup your relay will be turned on even if you invert its output later. So when you're looking for a relay module, avoid ones with a "JD-VCC" jumper (these require modification to work with 3.3v signals) and pick one with a set of configurable active-low/high jumpers (mine are labelled LOW-COM-HEIGHT, ha!).
Connect DC+ to the same 5v power supply as your Pi, DC- to ground, and IN1 to IN4 to the GPIO pins. If you're using the RpiGpioSetup package, these will be GPIO21, 17, 27 and 22 (header pins 40, 11, 13 and 15). The full list is here. Make sure the low/high jumpers are set to high.

Next, set up the inverter. My Multiplus 1600 is a smaller model without digital inputs, but it does have an input for a battery temperature sensor which can be reconfigured. Since mine is connected to the Pi via a VE.Bus to USB cable, it uses data from the battery monitor for temperature-compensated charging, so this input is spare.
You can use Victron's VEConfigure software over USB, but if it's connected to the Pi it's much easier to configure remotely through the VRM. Go to Device list -> Remote VEConfigure and click Download to get the config file. Open VEConfigure, choose Port selection then Fake target from file and pick the downloaded file.
First, go to the Virtual switch tab and set Do not use VS (it's incompatible with assistants). Then, go to Assistants, add a General flag user and click Start assistant to configure it. Do the same again to add two Programmable relays. Configure them as follows:
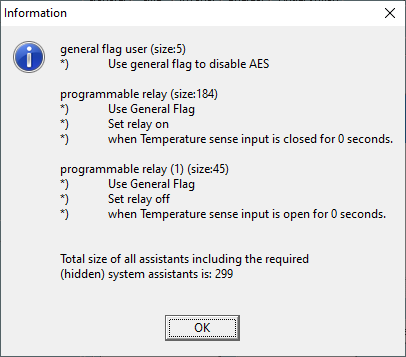
The "general flag" is a virtual switch that you can use to activate various features. Here, we use it to disable AES when it's "on". We then use a programmable relay to activate the flag when the temperature sense input is shorted, and another to deactivate it when it's open-circuit.
Close VEConfigure (don't use the save function in the menu), and save the file when prompted. Go back to the VRM, click Upload and choose the file. The inverter will reset a couple of times.
Now, connect the relay (COM and NO) to the temperature sense input. Either way round is fine. Use a small screwdriver to press in the orange tabs so you can insert the wires. I recommend ferrules if you want it to look neat!

The simplest solution would have been to connect a switch or button to the input to disable AES - flick the switch or hold the button for a few seconds until the load picks up. But since we're in it already, let's add a couple of buttons to our Node-RED dashboard.
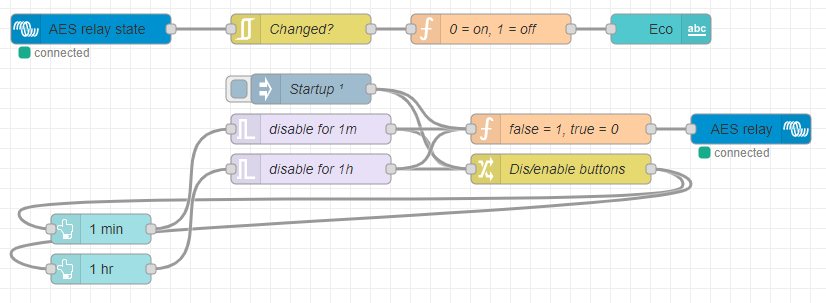
As usual, this is more complicated than it needs to be. You can grab the completed flow from my Github. I added two buttons, one for 1 minute and one for 1 hour. These activate trigger nodes, which send false immediately, then true after the specified time. false and true go to a change node, which sets msg.enabled from the payload and feeds this back to the buttons, disabling them until the timer runs out. They also go to a function node, which converts false to 1 and true to 0, activating the relay. I also added a relay state node which displays on the dashboard whether AES is on or off. Finally, I added a node which runs 0.1s after startup, turning off the relay and enabling the buttons in case the timer has been cancelled by a restart. Here's what it looks like in the dashboard:


And that's it! As always, drop a comment if you have any questions or made anything cool out of it 🙂






{kind=link}